Dans leur Atelier-Données du 5 juillet 2021 (Rivet & Valeins, 2021) mettent en évidence le coût de la non-qualité des données en ces termes : « Harvard Business Review estimait en 2017 qu’une tâche effectuée avec une donnée erronée engageait un coût 100 fois supérieur à celui d’une tâche réalisée à partir d’une donnée initialement vérifiée et correcte. » puis nous alarment sur l’étendue de la problématique « Selon l’analyse Gartner 2020 sur les solutions de gestion de qualité des données, plus de 25 % des données critiques des plus grandes entreprises sont erronées, au point que le coût moyen d’une mauvaise qualité des données pourrait s’élever à 11M€ par an pour les organisations. Les répercussions économiques, positives ou négatives, sont donc à considérer avec la plus grande attention. »
Pour Laure Berti-Equille (Berti-Equille, 2012) la qualité des données peut être analysée selon 9 indicateurs : Pertinence, Accessibilité, Facilité d’interprétation, Unicité, Cohérence, Conformité, Exactitude, Complétude et Consistance. Il serait trop long de détailler ici chacune de ces caractéristiques, notons cependant que pour l’auteure « les principaux défauts qui peuvent résulter des erreurs humaines ou des défaillances logicielles durant le cycle de vie d’une application sont : les doublons, les données manquantes ou incomplètes, les valeurs non standards, les inconsistances, les laveurs inexactes, les données obsolètes et inutiles ».
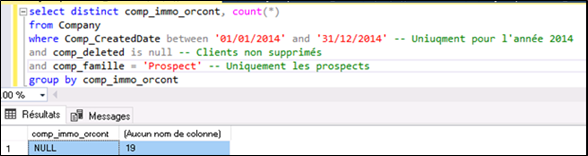
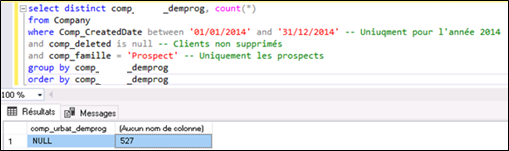
Au lancement du projet les données présentes dans le CRM sont affectées, de manière plus ou moins forte, par l’ensemble de ces défauts. Aussi, afin de déterminer le niveau de ces défauts, afin de mesurer la qualité des données, il est impératif d’explorer de manière pragmatique, les différentes bases de données, les différentes tables, d’analyser les résultats obtenus grâce aux requêtes SQL, de valider ces résultats ou de les faire valider par les opérationnels, puis d’affiner progressivement les requêtes de sélection. Une fois de plus c’est un long travail qui pourrait, sous, certains aspects s’apparenter à la phase de « nettoyage amont » des données. Ce qui ne sera pas nettoyé en amont sera ensuite écarté ou transformé dans les différentes requêtes de sélection. Voyons ceci sur quelques exemples.
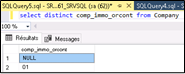
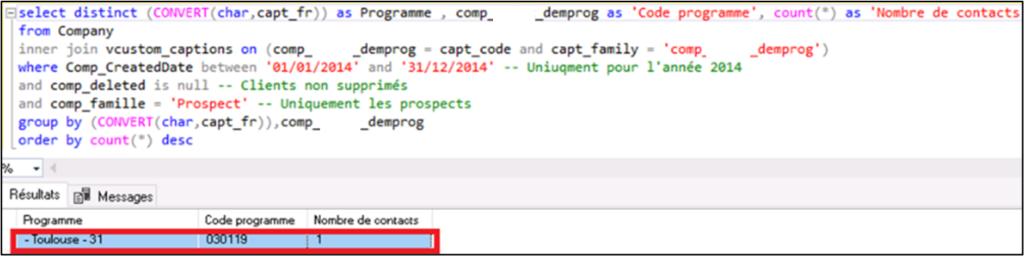
Par exemple, en analysant les données de manière tout à fait élémentaire la première des choses est de savoir si la donnée dont nous avons besoin dans notre rapport est systématiquement saisie. En langage SQL une requête de type SELECT DISTINCT nous permet de savoir où nous en sommes. Afin d’illustrer la démarche, à titre d’exemple, nous allons, ci-après, vérifier la qualité des données pour les axes Origine, Programme, Agence et Rendez-vous. A titre d’exemple car ce travail est, en réalité, bien plus fastidieux et plus complexe.
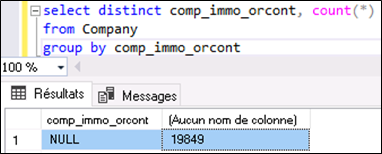
Origines : Donnée indispensable pour la plupart des rapports à construire. Voyons si elle est systématiquement renseignée dans la fiche prospect en exécutant une requête sur la table Company. La présence de la ligne NULL (voir Figure 6) interroge. Elle prouve que l’information n’est pas systématiquement saisie.